
This write-up is an insight into the service-oriented architecture of Bazaarvoice that they wrote from the ground up and moved their workload in parts following the divide & conquer approach from the existing monolithic architecture.
The new architecture sailed them smoothly through events like Black Friday and Cyber Monday serving record traffic of over 300 million visitors.
At peak, the Bazaarvoice platform handled over 97k requests per second, serving over 2.6 billion review impressions, with a 20% increase over the former year.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
The Original Monolithic Architecture
Originally, Bazaarvoice had a Java-based monolithic architecture. The UI was rendered server-side.
With custom deployments, tenant partitioning and horizontal read scaling of MySQL/Solr architecture, they managed the traffic pretty well.
But as the business grew, new business use cases emerged like the need to display customer reviews across multiple e-commerce & social portals.
This was handled by copying the reviews many times over throughout the network but the approach wasn’t scalable & expensive as the data grew pretty fast.
Below is the monolithic architecture diagram of the Bazaarvoice platform
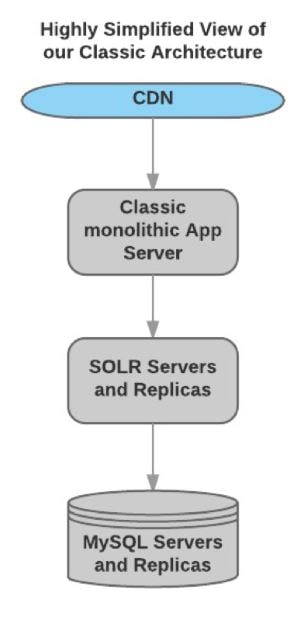
The aim of the engineering team was to have an efficient system in place to manage fast-growing data, render UI on the client and migrate the workload to a distributed service-oriented architecture.
The need for managing big data and transitioning to a distributed architecture is understandable. But why the need for client-side rendering?
Why Client-Side Rendering? What were the Problems with Server-Side Rendering?
Client-side vs Server-side rendering deserves a separate write-up in itself. I’ll just quickly provide the gist, the pluses & minuses of the two approaches.
Server-side rendering means the HTML is generated on the server when the user requests a page. This ensures faster delivery of the UI, avoiding the whole UI loading time in the browser window, as the page is already created on the server and the browser doesn’t have to do much assembling and rendering work.
This kind of approach is perfect for delivering static content, such as wordpress blogs. Good for SEO as the crawlers can easily read the generated content.
But since modern websites are so AJAX-based. The required content for a particular module or section of a page is fetched and rendered on the fly.
Server-side rendering doesn’t help much as for every AJAX request instead of sending just the required content to the client, the approach generates the entire page. This consumes unnecessary bandwidth in addition to failing to provide a smooth user experience.
A big downside to the server-side rendering approach is once the number of concurrent users on the website rises, it puts an unnecessary load on the server. In contrast, the client-side rendering works best for modern dynamic AJAX-based websites.
Also we can also leverage a hybrid approach to get the most out of both techniques. We can use server-side rendering for the home page, also for other static content on our website and client-side rendering for the dynamic pages.
Technical Insights
Bazaarvoice adopted big data distributed architecture based on Hadoop & HBase to stream data from hundreds of millions of websites into its analytics system.
Recommended read: An insight into databases leveraged by Twitter.
Understanding this data would delineate the entire user flow which would help Bazaarvoice clients to study user shopping behavior.
As the primary display storage, Cassandra, which is a wide-column open-source NoSQL data store, was picked. This technology choice was inspired by Netflix’s use of Cassandra as a data store.
On top of Cassandra, they built a custom service called Emo, which was intended to overcome the potential data consistency issues in Cassandra in addition to guaranteeing ACID database operations.
For the search use cases, ElasticSearch was picked with a flexible rules engine called Polloi to abstract away the indexing & aggregation complexities from the team that would use the service.
The workload is deployed on the AWS Cloud which also helped them manage monitoring, elasticity & security.
The entire existing workload was moved to the service-oriented AWS cloud part by part following a divide & conquer approach to avoid any major blow-ups.
Below is a new service-oriented architectural diagram of the Bazaarvoice platform
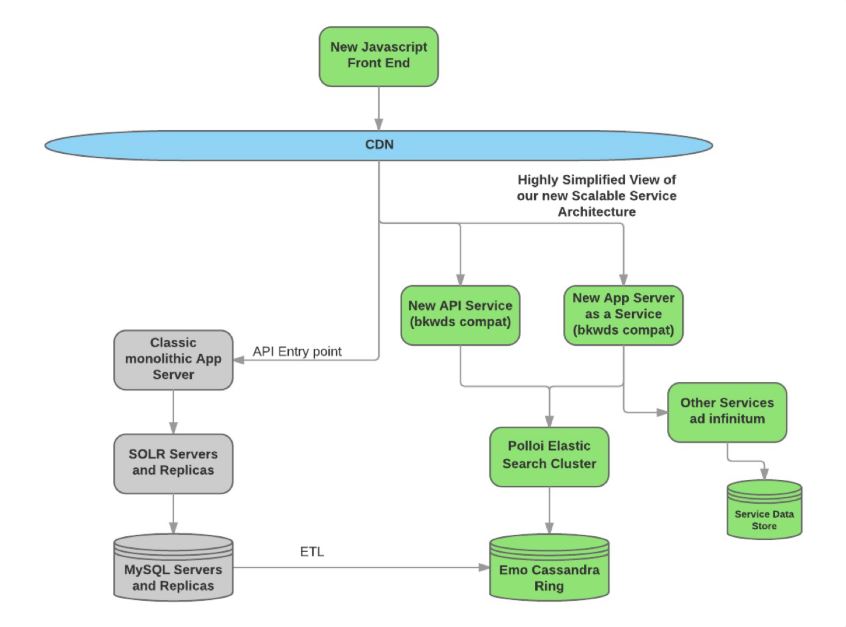
Originally, the customers used a template-based front end. The engineering team wrote a new client-side rendering front end with JavaScript.
As you see in the diagram, the system as a whole has the original monolith and as well as the distributed design working in conjunction. This is due to the divide-and-conquer approach. Not all the customers were moved at once.
The engineering team wrote an API service that could be used to hit any of the monolithic or distributed service just by changing the API endpoint key.
With the initial start of moving a few clients at a time, the scalable architecture allowed them to move upto 500 customers at a time.
DevOps
All this massive engineering effort needed dedicated DevOps teams for monitoring, deployment, scalability and actively testing the performance of the workload running in the cloud.
The microservice architecture enabled different teams to take dedicated responsibility for the respective modules which is right from understanding the requirements to writing code, to running automated tests, to deployments, to 24*7 operations.
The platform infrastructure team developed a program called Beaver, an automated process that examined the cloud environment in real-time to ascertain that all the best practices were followed.
An additional service called the Badger monitoring service helped them automatically discover nodes as they spun up in the cloud.
A key takeaway from this massive engineering feat was, ‘Do not let the notion of having a perfect ideal implementation or transition of something hold you back.
Start small, keep iterating, keep evolving and keep moving ahead with patience. Celebrate each step of the architectural journey.’
It took them three years of hard work to pull this massive engineering feat of monolithic to microservices transition off.
Information source for this write-up;
Well, Folks! This is pretty much it. If you enjoyed reading the article, do share it with your network for better reach.
Check out the Zero to Mastering Software Architecture learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.

I’ll see you in the next article.
Until then.
Cheers!


Follow Me On Social Media