
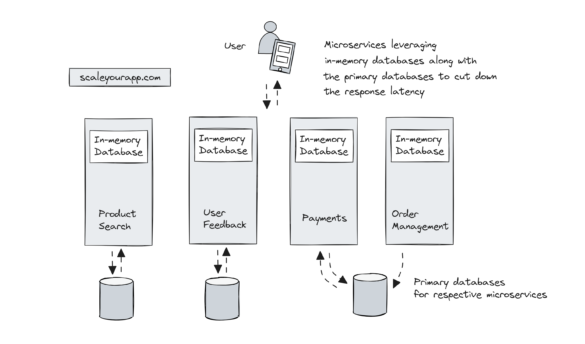
System Design Case Study #5: In-Memory Storage & In-Memory Databases – Storing Application Data In-Memory To Achieve Sub-Second Response Latency
In the last few write-ups on this blog, I’ve dug deep into the aspect of storing application data in-memory to reduce the service response latency. I started with a discussion on Slack’s real-time messaging architecture. Slack sends millions of messages daily across millions of Slack...
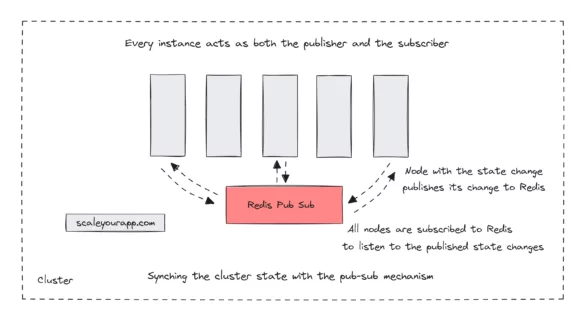
System Design Case Study #4: How WalkMe Engineering Scaled their Stateful Service Leveraging Pub-Sub Mechanism
WalkMe Engineering had a stateful monolith service handling an average of 22.5 million monthly requests, peaking upto 30 million. The service managed this massive load sustained by vertical scaling but started to show cracks as a single monolith server can be vertically scaled only so...
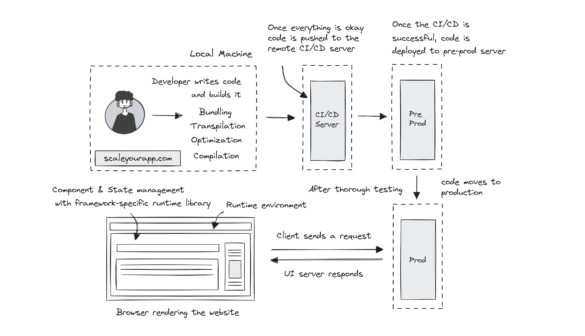
Why Stack Overflow Picked Svelte for their Overflow AI Feature And the Website UI
Stack Overflow is a .NET-based monolithic application with JQuery heavily used on the UI along with the Razor templating engine for creating dynamic web pages. JQuery in today’s UI dev landscape has almost phased out. Modern browsers have evolved their native APIs to the point...
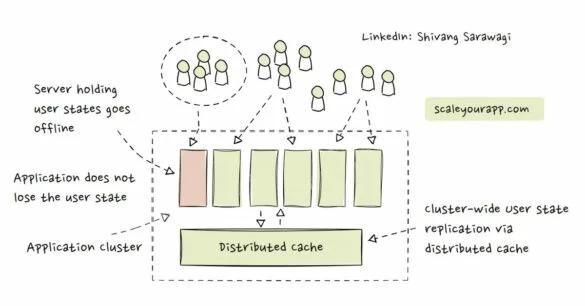
A Discussion on Stateless & Stateful Services (Managing User State on the Backend)
In most articles I come across on stateless and stateful services, stateful service architectures are viewed less favorably in contrast to stateless services primarily due to the horizontal scalability challenge they bring along. It is always recommended to implement a stateless service architecture as opposed...
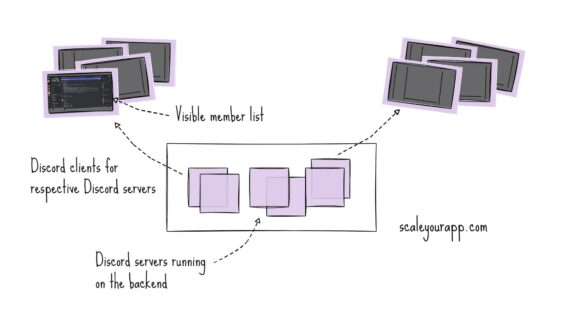
System Design Case Study #3: How Discord Scaled Their Member Update Feature Benchmarking Different Data Structures
The member list update feature in Discord servers became quite a bottleneck in terms of memory & CPU usage because the system had to update the entire member list in every Discord server every time someone joined or left the server, changed their status (online,...
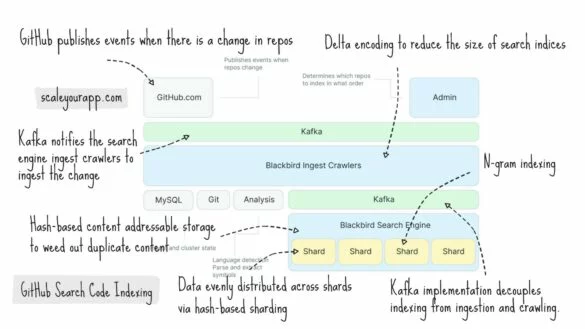
System Design Case Study #2: How GitHub Indexes Code For Blazing Fast Search & Retrieval
GitHub coded their search engine from scratch in Rust called Project Blackbird because existing off-the-shelf solutions didn’t fit their requirements at the scale they were operating. The engine supports features like searching with identifiers, punctuations, substrings, regular expressions, wildcards, etc., which are specific to code...
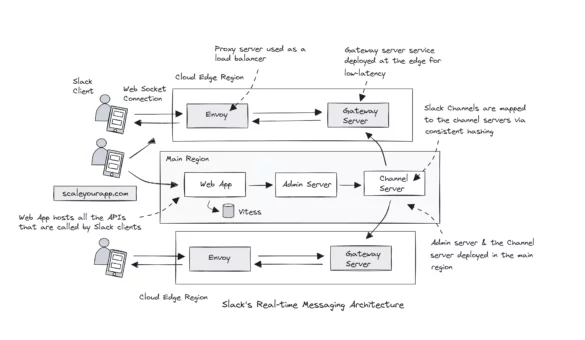
System Design Case Study #1: Exploring Slack’s Real-time Messaging Architecture
In this blog post, I explore Slack’s real-time messaging architecture with a discussion on the architectural and system design concepts they leverage to scale and keep the latency low. The study will help us understand the intricacies of real-world web-scale architectures, enhancing our system design...
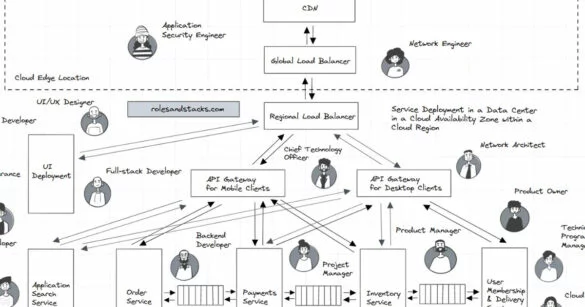
Web Service & Associated IT Roles
Below is the high-level application architecture of a virtual global e-commerce service specializing in selling books to customers worldwide deployed in a data center in a cloud availability zone within a cloud region. The web components (CDN, load balancers, API gateways, microservices, databases, etc.) and...
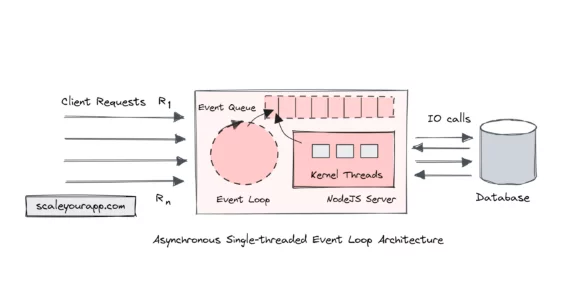
Single-threaded Event Loop Architecture for Building Asynchronous, Non-Blocking, Highly Concurrent Real-time Services
Real-time services like chat apps, MMO (Massive Multiplayer Online) games, financial trading systems, apps with live streaming features, etc., deal with heavy concurrent traffic and real-time data. These services are I/O bound as they spend a major chunk of resources handling input-output operations such as...
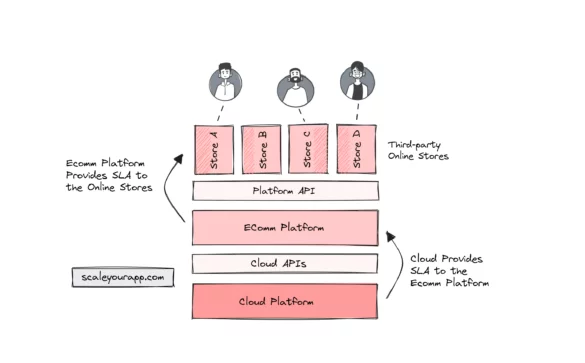
Understanding SLA (Service Level Agreement) In Cloud Services: How Is SLA Calculated In Large-Scale Services?
An SLA (Service Level Agreement) is a contract or agreement between a service provider and the consumer that defines the expectations a consumer should have from the service provided by the service provider. An SLA helps maintain service standards and establishes service providers’ accountability towards...
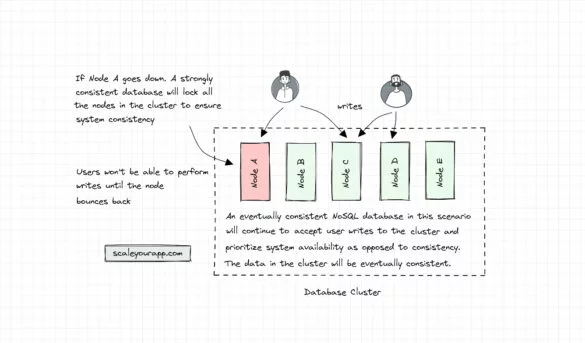
Database Architecture – Part 2 – NoSQL DB Architecture with ScyllaDB (Shard Per Core Design)
In the first post of database architecture, I discussed the internal architecture of databases/database management systems, taking a peek into the architectures of MySQL and CockroachDB databases. In another article, a continuation of that article, I discussed how modern cloud servers run parallel compute to...
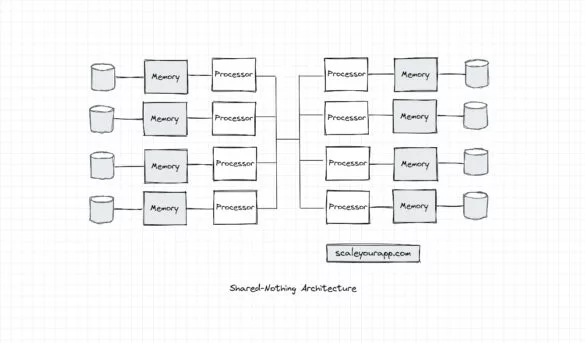
Parallel Processing: How Modern Cloud Servers Leverage Different System Architectures to Optimize Parallel Compute
Modern cloud servers leverage several system architectures to process data parallelly, which increases throughput, minimizes latency and optimizes resource consumption. In this article, I’ll discuss those system architectures and we’ll get an insight into how distributed services leverage these architectures to scale. With that being said....


Follow Me On Social Media