
Facebook database [Updated] – A thorough insight into the databases used @Facebook
This write-up is a comprehensive insight into the persistence layer of Facebook and the first of the distributed systems write-ups on this blog. It takes a deep dive into questions like what database does Facebook use? Is it a NoSQL or a SQL DB? Is it just one or multiple databases? Or a much more complex polyglot database architecture? How is Facebook’s backend handling billions of data fetch operations every single day?
So, without further ado.
Let’s get started.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
1. What database does Facebook use?
If you need a quick answer here it is:
MySQL is the primary database used by Facebook for storing all social data. They started with the InnoDB MySQL database engine and then wrote MyRocksDB, which was eventually used as the MySQL Database engine.
Memcache sits in front of MySQL as a cache.
To manage BigData Facebook leverages Apache Hadoop, HBase, Hive, Apache Thrift and PrestoDB. All these are used for data ingestion, warehousing and running analytics.
Apache Cassandra is used for the inbox search
Beringei and Gorilla, high-performance time-series storage engines are used for infrastructure monitoring.
LogDevice, a distributed data store is used for storing logs.
Now let’s delve into the specifics.
1.1 PolyGlot persistence architecture
Facebook, today, is not a monolithic architecture. It might have been at one point in time like LinkedIn was and Uber was but definitely not today.
The social network as a whole consists of several different loosely coupled components plugged in together like Lego blocks. For instance, photo sharing, messenger, social graph, user posts, etc. are all different loosely coupled microservices running in conjunction with each other. And every microservice has a separate persistence layer to keep things easy to manage.
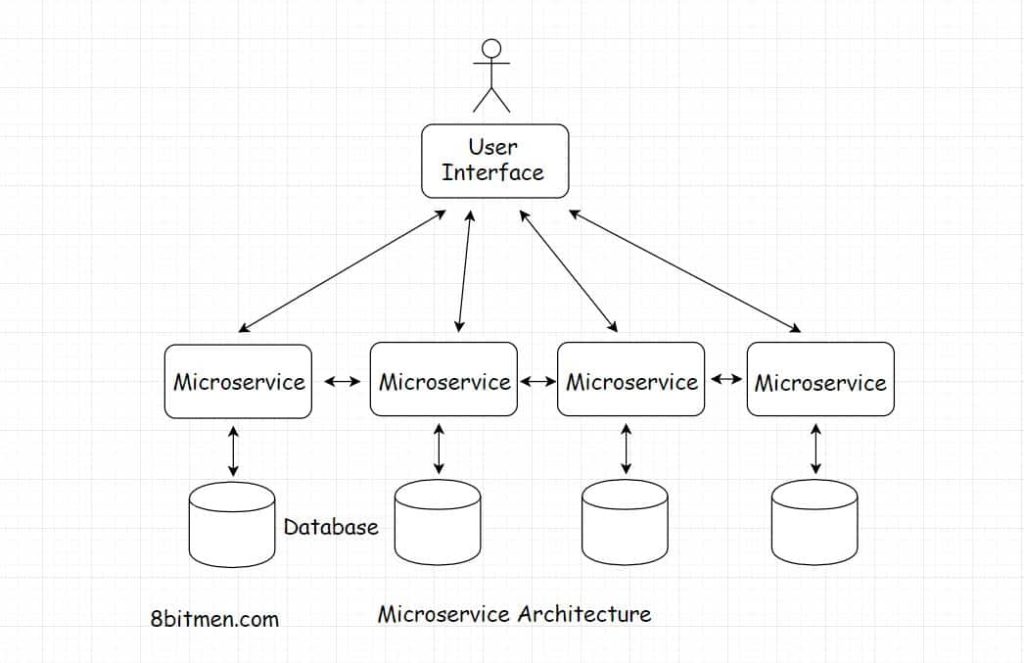
Polyglot persistence architecture has several upsides. Different databases with different data models can be leveraged to implement different use cases. The system is more highly available and easy to scale.
1.2 What is a polyglot persistence system?
Put in simple words, polyglot persistence means using different databases having unique features and data models for implementing different use cases of the system.
For instance, Cassandra and Memcache would serve different persistence requirements in contrast to a traditional MySQL DB.
If we have ACID requirements like for a financial transaction, MySQL would fit best. On the other hand, when we need fast data access, we would pick Memcache or when we are okay with data denormalization and it being eventually consistent but need a fast highly available database, a NoSQL solution would fit best.
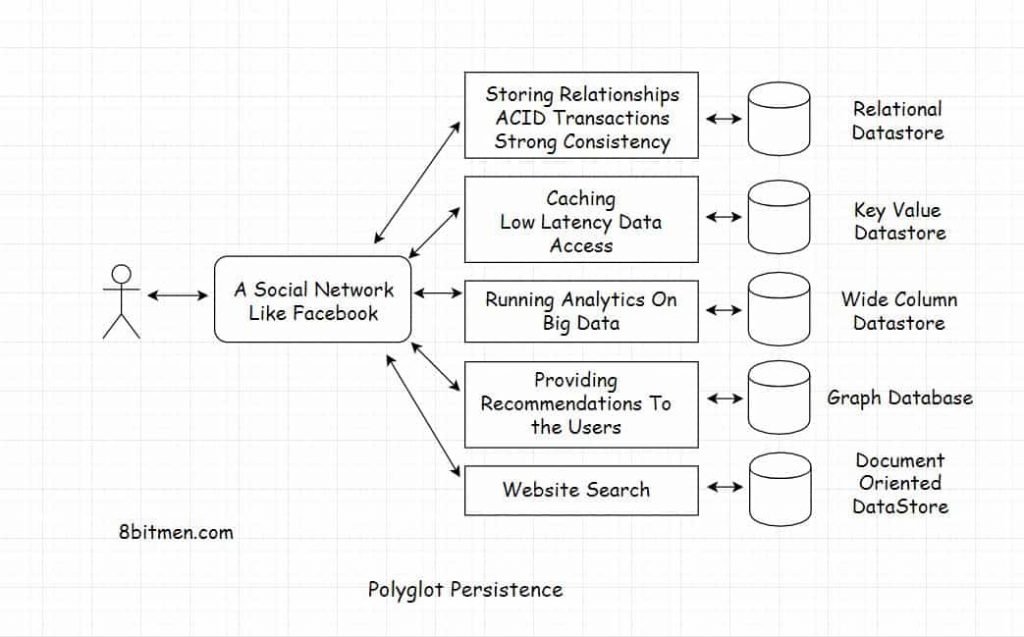
Given every technology has its use cases, Facebook leverages different persistence technologies to fulfill its different persistence requirements.
1.3 Does Facebook use a relational database system?
MySQL
This is the primary database that Facebook uses with different engines. Different engines? I’ll get to that.
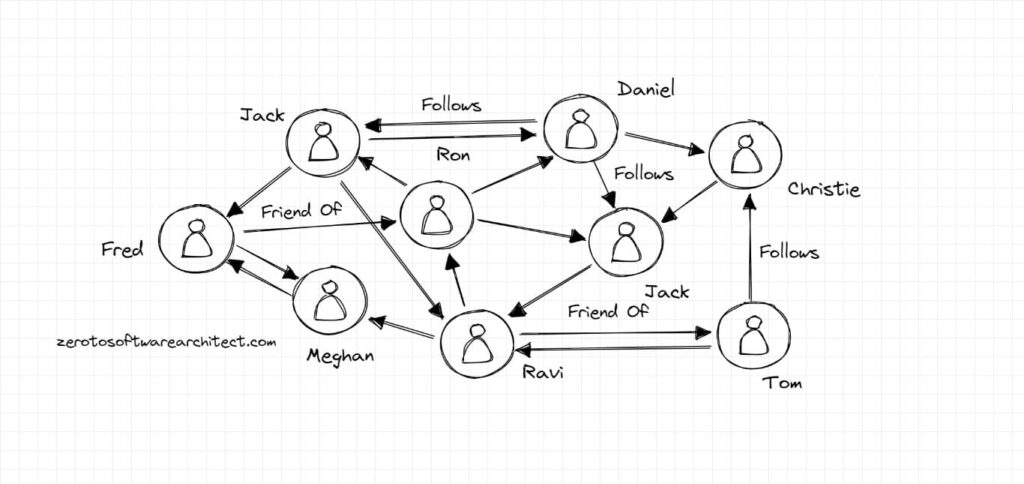
Facebook leverages a social graph to track and manage all the user events on the portal such as who liked whose post. Mutual friends. Which of your friends already ate at the restaurant you are visiting and so on. And this social graph is powered by MySQL.
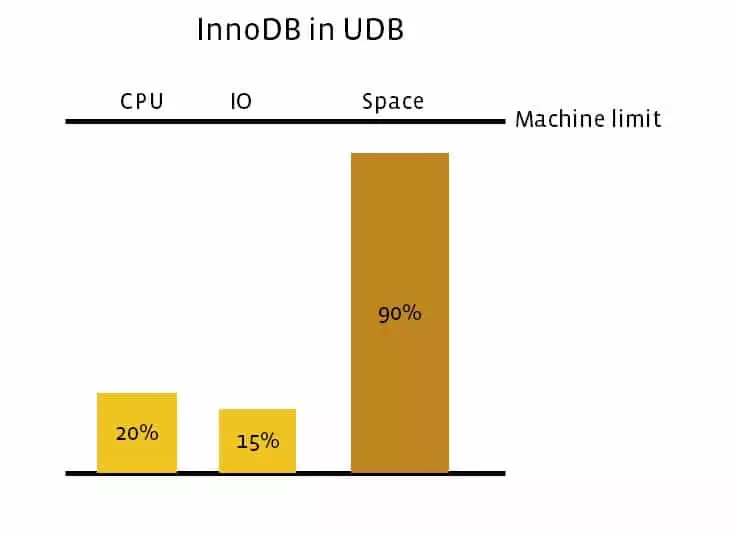
Initially, the Facebook engineering team started with MySQL InnoDB engine to persist social data. Data took too much storage space despite being compressed. More space usage meant more hardware requirements which naturally spiked the data storage costs.
InnoDB MySQL storage engine
InnoDB is the default MySQL storage engine that provides high reliability and performance.
InnoDB architecture
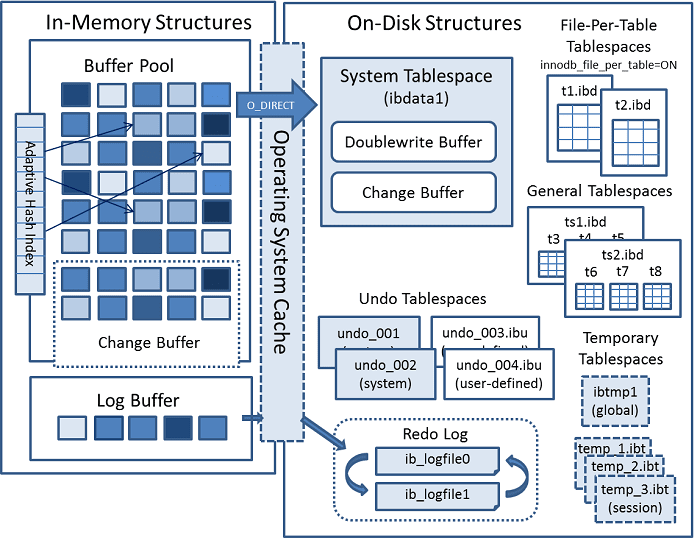
MyRocks MySQL storage engine written by Facebook
To deal with the space issues. The engineering team at Facebook wrote a new MySQL database engine MyRocks which reduced space usage by 50% and also helped improve the write efficiency.
Over time Facebook migrated its user-facing database engine from InnoDB to MyRocks. The migration didn’t have much difficulty since just the DB engines changed and the core tech MySQL was the same.
After the migration, for a long while, the engineering team ran data consistency verification checks to check if everything went smooth.
Several benchmark processes were run to evaluate the DB performance and the results stated that MyRocks instance size turned out to be 3.5 times smaller than the InnoDB instance uncompressed and 2 times smaller than the InnoDB instance compressed.
WebScale SQL
MySQL is the most popular persistence technology ever and is naturally deployed by big guns.
WebScale SQL is a collaboration amongst engineers from several different companies such as Google, Twitter, LinkedIn, Alibaba running MySQL in production at scale to build and enhance MySQL features that are required to run in large-scale production environments.
Facebook has one of the largest MySQL deployments in the world. And it shares a common WebScale SQL development codebase with the other companies.
The engineering team is Facebook is preparing to move its production-tested versions of table, user and compression statistics into WebScaleSQL.
If you want to master databases comprising concepts like relational and non-relational databases, when to pick which, eventual consistency, strong consistency, different types of databases (relational, document-oriented, key-value, wide-column, graph, etc.), what use cases fit them, how applications and databases handle concurrent traffic, how we manage database growth dealing with petabytes of data, how they manage data consistency when deployed in different cloud regions and availability zones around the globe and much more, check out the Zero to Software Architect learning track that I’ve written comprising three courses. I wish I had something similar to learn from in the initial years of my career.
2. RocksDB: A persistent key-value store for Flash and RAM storage
Initially, Facebook wrote an embeddable persistent key-value store for fast storage called RocksDB. Which being a key-value store had some advantages over MySQL. RocksDB was inspired by LevelDB a data store written by Google.
It was sure fast but did not support replication or an SQL layer and the Facebook engineering team wanted those MySQL features in RocksDB. Eventually, they built MyRocks, an open-source project that had RocksDB as a MySQL storage engine.
RocksDB fits best when we need to store multiple terabytes of data in one single database.
Some of the typical use cases for RocksDB:
1. Implementing a message queue that supports a large number of inserts & deletes.
2. Spam detection where you require fast access to your dataset.
3. A graph search query that needs to scan a data set in real time.
3. Memcache – A distributed memory caching system
Memcache is being used at Facebook right from the start. It sits in front of the database, acts as a cache, and intercepts all the data requests bolting toward the database.
Memcache helps reduce the request latency to a large extent eventually providing a smooth user experience. It also powers the Facebook social graph having trillions of objects and connections, growing every moment.
Memcache is a distributed memory caching system used by big guns in the industry such as Google Cloud.
Facebook caching model
When a user updates the value of an object, the new value is written to the database and the old value is deleted from Memcache. The next time user requests that object, the updated value is fetched from the database and written to Memcache. Now after this for every request, the value is served from Memcache until it is modified.
This flow appears pretty solid until the database and the cache are deployed in a distributed environment. Now eventual consistency comes into effect.
The instances of an app are geographically distributed. When one instance of a distributed database is updated, say in Asia, it takes a while for the changes to cascade to all of the instances of the database running globally.
Now right at a point when the value of an object is updated in Asia, a person requesting that object in America will receive the old value from the cache.
This is typically a tradeoff between high availability and data consistency.
4. How does Facebook manage BigData?
4.1 Apache Hadoop
Well, this shouldn’t come as a surprise, Facebook has an insane amount of data that grows every moment. And they have an infrastructure in place to manage such an ocean of data.
Read this article on data ingestion to understand why it is super important for businesses to manage and make sense of large amounts of data.
Apache Hadoop is the ideal open-source utility to manage big data and Facebook uses it for running analytics, distributed storage and storing MySQL database backups.
Besides Hadoop, there are also other tools like Apache Hive, HBase and Apache Thrift that are used for data processing
Facebook has open-sourced the exact versions of Hadoop that they run in production. They have possibly the biggest implementation of the Hadoop cluster in the world. Processing approx. 2 petabytes of data per day in multiple clusters at different data centers.
If you wish to understand how distributed systems are deployed and scaled across the globe in the cloud, how nodes work together in a cluster, deployment workflow, deployment infrastructure, the associated technologies and much more, check out my Cloud Computing 101 – Master the Fundamentals course.
Facebook messages use a distributed database called Apache HBase to stream data to Hadoop clusters. Another use case is collecting user activity logs in real-time in Hadoop clusters.
4.2 Apache HBase deployment at Facebook
HBase is an open-source, distributed database, non-relational in nature, inspired by Google’s BigTable. It is written in Java.
Facebook Messaging Component originally used HBase, running on top of HDFS. It was chosen by the engineering team due to the high write throughput and low latency it provided. The other features, it being a distributed project, included horizontal scalability, strong consistency & high availability. Now the messenger service uses RocksDB to store user messages.
HBase is also used in production by other services such as the internal monitoring system, search indexing, streaming data analysis and data scraping.
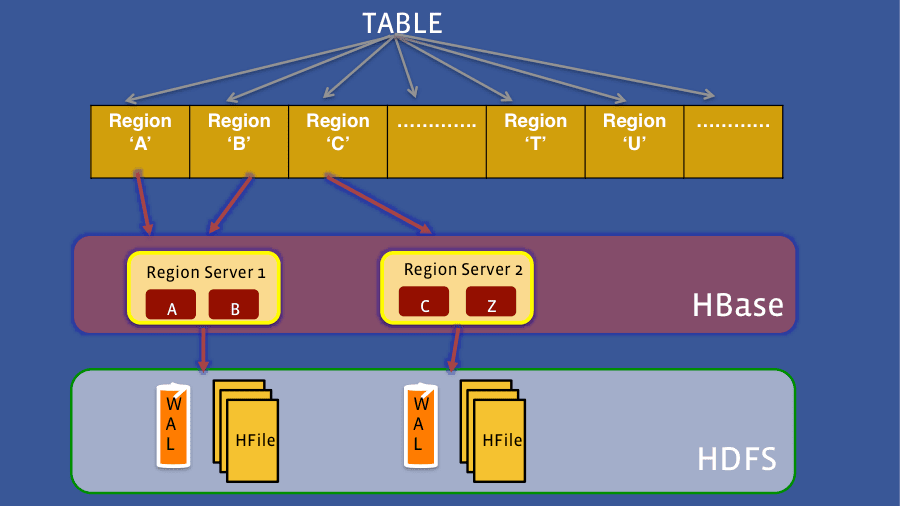
Migration of messenger storage from HBase to RocksDB
The migration of the messenger service database from HBase to RocksDB enabled Facebook to leverage flash memory to serve messages to its users as opposed to serving messages from the spinning hard disks. Also, the replication topology of MySQL is more compatible with the way Facebook data centers operate in production. This enabled the service to be more available and have better disaster recovery capabilities.
4.3 Apache Cassandra – A distributed wide-column store
Apache Cassandra is a distributed wide-column store built in-house at Facebook for the Inbox search system. Cassandra was written to manage structured data and scale to a very large size across multiple servers with no single point of failure.
The project runs on top of an infrastructure of hundreds of nodes spread across many data centers. Cassandra is built to maintain a persistent state in case of node failures. Being distributed features like scalability, high performance and high availability are inherent.
4.4 Apache Hive – Data warehousing, query & analytics
Apache Hive is a data warehousing software project built on top of Hadoop for running data query and analytics.
At Facebook, it is used to run data analytics on petabytes of data. The analysis is used to gain insight into user behavior, it helps in writing new components and services, also understanding user behavior for Facebook Ad Network.
Hive inside Facebook is used to convert SQL queries to a sequence of map-reduce jobs that are then executed on Hadoop. Writing programmable interfaces and implementations of common data formats & types to store metadata etc.
5. PrestoDB – A high-performing distributed relational database
PrestoDB is an open-source performant, distributed RDBMS primarily written for running SQL queries against massive amounts, like petabytes of data. It’s an SQL query engine for running analytics queries. A single Presto query can combine data from multiple sources, enabling analytics across the organization’s system.
The DB has a rich set of capabilities enabling data engineers, scientists and business analysts to process Tera to Petabytes of data.
Facebook uses PrestoDB to process data via a massive batch pipeline workload in their Hive warehouse. It also helps in running custom analytics with low latency and high throughput. The project has also been adopted by other big guns such as Netflix, Walmart, Comcast, etc.
The below diagram shows the system architecture of Presto
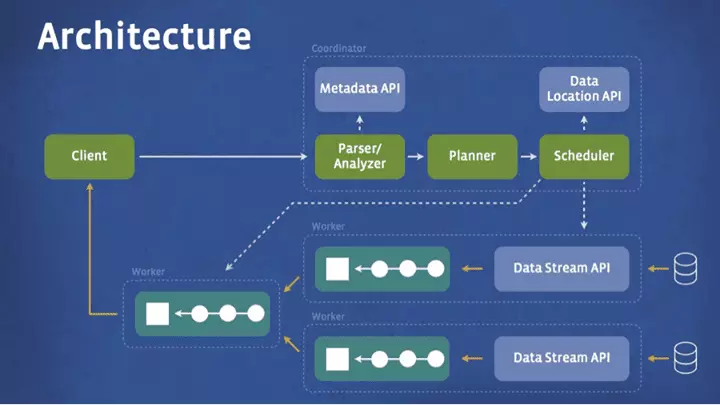
The client sends an SQL query to the Presto coordinator. The coordinator then parses, analyzes and plans the query execution. The scheduler assigns the work to the nodes located closest to the data and monitors the processes.
The data is then pulled back by the client at the output stage for results. The entire system is written in Java for speed. Also, it makes it really easy to integrate with the rest of the data infrastructure as they too are written in Java.
Presto connectors are also written to connect with different data sources.
6. Beringei: A high-performance time-series storage engine
Beringei is a time series storage engine and a component of the monitoring infrastructure at Facebook. The monitoring infrastructure helps in detecting the issues and anomalies as they arise in real-time.
Facebook uses the storage engine to store system measurements such as product stats like how many messages are sent per minute, the service stats, for instance, the rate of queries hitting the cache vs the MySQL database. Also, the system stats like the CPU, memory and network usage.
All the data goes into the time series storage engine and is available on dashboards for further analysis. Ideally in the industry Grafana is used to create custom dashboards for running analytics.
7. Gorilla: An in-memory time-series database
Gorilla is Facebook’s in-memory time series database primarily used in monitoring and analytics infrastructure. It is intelligent enough to handle failures ranging from a single node to entire regions with little to no operational overhead. The below figure shows how gorilla fits in the analytics infrastructure.
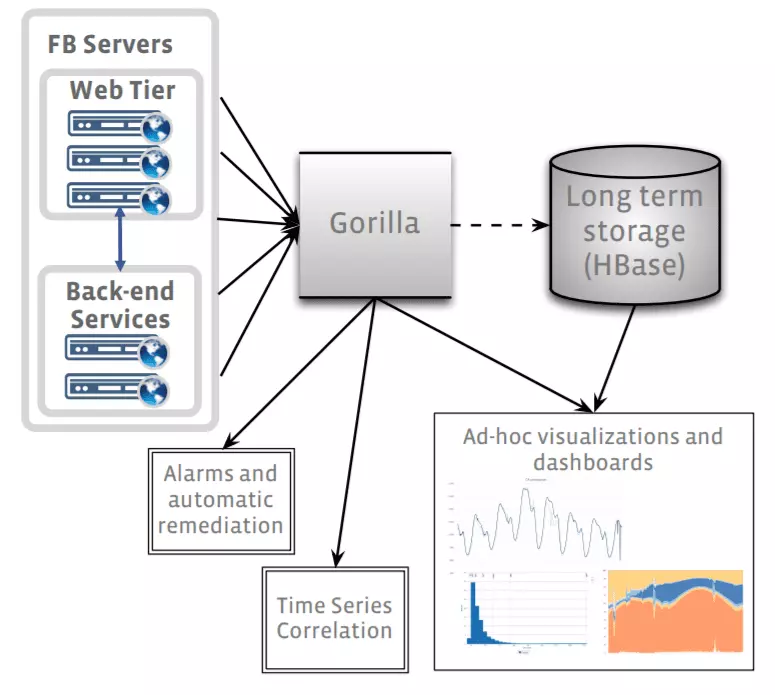
Since deployment Gorilla has almost doubled in size twice in the 18-month period without much operational effort which shows the system is pretty scalable. It acts as a write-through cache for monitoring data gathered across all of Facebook’s systems. Gorilla reduced Facebook’s production query latency by over 70x when compared with the previous stats.
8. LogDevice: A distributed data store for logs
Logs are the primary way to track the bugs occurring in production, they help in understanding the context & writing a fix. No system can run without logs. And a system of the size of Facebook where so many components are plugged in together generates a crazy amount of logs.
To store and manage all these logs Facebook uses a distributed data store for logs called LogDevice.
It’s a scalable and fault-tolerant distributed log system. In comparison to a file system that stores data as files, LogDevice stores data as logs. The logs are record-oriented, append-only & trimmable. The project has been written from the ground up to serve multiple types of logs with high reliability and efficiency at scale.
The kind of workloads supported by LogDevice are event logging, stream processing, ML training pipelines, transaction logging, replicated state machines, etc.
9. Conclusion
Folks, this is pretty much it. I did quite a bit of research on the persistence layer of Facebook and I believe I’ve covered all the primary databases deployed at Facebook.
Also, this article will be continually updated as Facebook’s systems evolve. Here are a few recommended reads:
Recommended reads:
Facebook real-time chat architecture scaling with over multi-billion messages daily
Facebook’s Photo Storage Architecture
If you found the content helpful, consider sharing it with your network for better reach. I am Shivang. You can catch me on LinkedIn here.
If you wish to master the fundamentals of software architecture covering all the components of a large-scale distributed web application, check out the Zero to Software Architect learning track written by me.

Subscribe to the newsletter to stay notified of the new posts.


Follow Me On Social Media