
This article is an insight into data ingestion. It will answer your queries such as What is data ingestion? What are the present challenges organizations are facing ingesting data in real-time and in batches? How to pick the right data ingestion tool? and such.
So, without further ado. Let’s get started.
1. What is Data Ingestion?
Data Ingestion is the process of streaming massive amounts of data into our system from several different external sources for running analytics and other data-related operations as required by the business.
Businesses do this to extract meaningful information from massive amounts of data that enables them to make future business decisions.
1.1 Where Does this Massive Amount Of Data Come From?
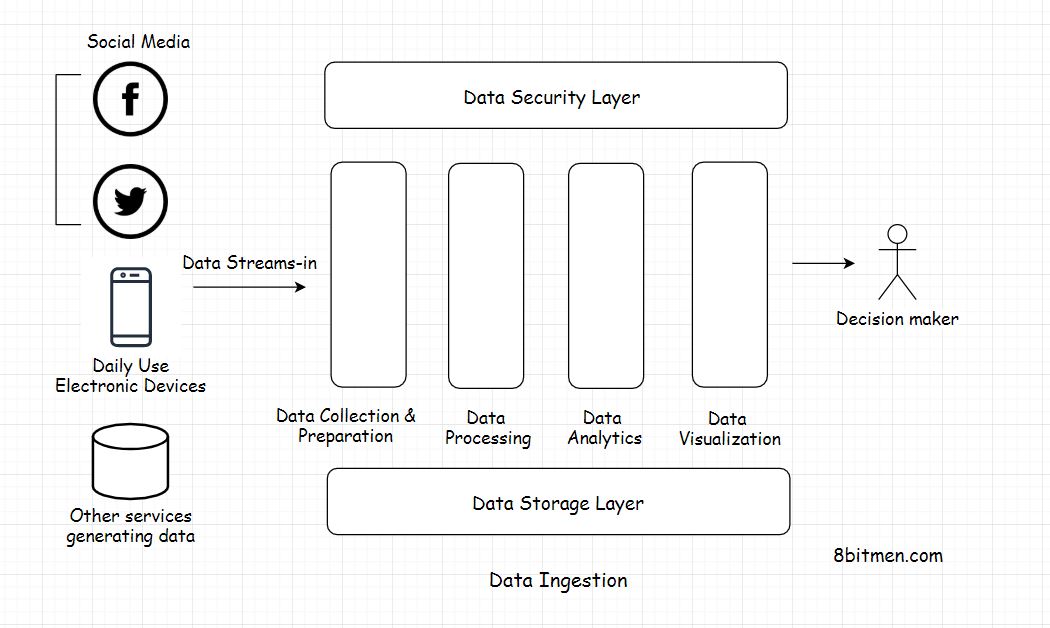
The data is primarily user-generated, generated from IoT devices, social networks and such, that is continually recorded helping our systems evolve resulting in an enhanced user experience.
Data ingestion is one part of a much bigger data processing system. Big data moves into our system through a data pipeline through several different stages.
In the entire big data processing setup there are several different layers involved such as the data collection layer, data query layer, data processing, data visualization, data storage and the data security layer.
1.2 What are the Different Ways of Ingesting Data?
Data ingestion can be done in either real-time or in batches at regular intervals. This entirely depends on the business use case.
Real-time data Ingestion is typically preferred in systems where it is critical to get the latest data as soon as possible, for instance, getting access to medical data like heartbeat, blood pressure, etc. from medical IoT sensors, financial data involving stock market events, etc. Time is of the essence here.
On the contrary in systems that read trends over time, for instance, estimating the popularity of a sport in a certain geographic region over a period of time, the data can be ingested in batches.
1.3 Why Is Data Ingestion Important?
Businesses need to study data to make future plans and projections. This helps them understand the customer’s needs and behaviors. This enables businesses to create better products, make smarter decisions, run better ad campaigns, provide accurate user recommendations and such. And this eventually results in better customer-centric products with increased customer loyalty.
Another use case of data ingestion is infrastructure monitoring. Keeping an eye on the data streaming in, getting an ‘everything is okay’ signal from IoT devices used by millions of customers helps us track the service efficiency.
Besides data streaming in from external sources, it can also be streamed in from different internal system components into a central pipeline, for instance, a log pipeline that ingests logs from different system components or services.
This facilitates better log management by streaming logs into a log processing system like the ELK stack. Let’s peek further into real-world industry data ingestion use cases.
2. Real-World Industry Data Ingestion Use Cases
Moving Massive Amounts of Big Data into Hadoop
Moving big data through data pipelines into a distributed data processing framework like Hadoop is the most common use case of data ingestion.
Moving Data from Databases to Elastic Search Server
To power the search component in web applications data from different databases in a distributed service is streamed into the Elasticsearch server. And this happens continually at stipulated intervals. All the search results are powered by the search server.
Log Processing And Running Log Analytics Systems
Most popular real-world services are distributed in nature with several hundreds, even thousands of microservices running in conjunction. With so many services, there is a massive number of logs that are generated over time.
All the logs are streamed to a central place to run analytics on with the help of solutions like the ELK stack.
Stream Processing Engines For Real-Time Events
Low-latency real-time streaming and data processing is key in systems handling LIVE information such as sports and news. It’s imperative that the application architecture in place is efficient enough to ingest data and analyze it at the required speed. Data ingestion is a key thing here as well.
If you wish to take a deep dive into how real-time streaming systems are designed and more, check out my distributed systems design course here.
Let’s talk about some of the challenges development teams face while ingesting data.
3. Challenges Businesses Face When Ingesting Data
Slow Process
Data ingestion is a slow process. How exactly? When data is streamed from several different sources into the system, data incoming from different sources has a different format, syntax, attached metadata and so on. The data as a whole is heterogeneous. It has to be transformed into a standard format like JSON or something to be understood by the system.
The conversion of data is a tedious process. It takes quite a lot of computing power and time. Flowing data has to be staged at several stages in the pipeline, processed and then pushed ahead.
Also, at every stage data has to be authenticated and verified as well to comply with the organization’s security standards. With the traditional data cleansing processes, it takes weeks if not months to get useful information on hand. Traditional data ingestion systems like ETL ain’t that effective anymore when we require data ASAP.
Complex and Expensive
As discussed above the entire data flow process is resource-intensive. A lot of heavy lifting has to be done to prepare the data before being ingested into the system. Also, it isn’t a side process. An entire dedicated team is required to execute something like this.
IoT devices and other customer-facing services evolve at a quick pace with sometimes a change in the incoming data semantics. To avoid the system breaking, the backend has to be updated as well to ensure smooth data ingestion.
In addition, often there are scenarios where the tools and frameworks available in the market fail to serve our requirements and we are left with no option but to write a custom solution from the bare bones.
Data is Vulnerable
When data is moved around it opens up the possibility of a breach. Moving data is vulnerable. It goes through several different staging areas and the engineering team has to put in additional resources to ensure their system meets the security standards at all times.
4. Data Ingestion Architecture
Data ingestion is the initial and the most challenging part of the entire data processing architecture.
Here are the key parameters that must be considered when designing a data ingestion system:
Data velocity, size and format: Data streams in through several different sources into the system with different velocities, sizes and semantics. A data stream could be structured, unstructured, semi-structured and so on.
The frequency of data streaming: Based on the use case data can be streamed in either real-time or in batches at stipulated intervals. I’ve already discussed this in this article.
5. How To Choose the Right Data Ingestion Tool?
I’ve listed down a few things, a checklist, that I would keep in mind when researching a data ingestion tool:
1. The data pipeline should be fast, manageable and customizable with an effective data cleansing system.
2. If it’s an open-source solution, the upside of it is it can be extended based on the business requirements and can also be deployed on-prem with the data staying within the premises.
3. The tool should comply with all data security standards.
4. It should not have too much developer dependency. A person with not so much hands-on coding experience should be able to manage things.
For instance, it always helps to have no-code functionalities like a browser-based operations UI/dashboard via which business people can interact with data and run operations as opposed to having a console-based interaction system which would require specific commands to be fed into the system.
5. Market sentiment about the tool. Research if any existing scalable businesses have been using the solution. Go through their engineering blogs.
When researching the data ingestion tool. We need to be clear on our requirements. What kind of data we would be dealing with? On a high level, what would be our data management architecture? What scale are we talking about? Can the tool handle that data scale? and so on
6. Some Popular Data Ingestion Tools
Here is a list of some of the popular data ingestion tools:
Apache Nifi – Apache Nifi is a tool written in Java that automates the flow of data between different systems.
Gobblin By LinkedIn – Gobblin is a data ingestion tool by LinkedIn. At a point in time, LinkedIn had several data ingestion pipelines running in parallel which created some data management challenges. To tackle that LinkedIn wrote Gobblin in-house.
Apache Flume – Apache Flume is designed to handle massive amounts of log data.
Apache Storm – Apache Storm is a distributed stream processing computation framework primarily written in Clojure. The project went open source after it was acquired by Twitter.
Elastic Logstash – Logstash is a data processing pipeline that ingests data from multiple sources simultaneously.
Well, Folks! This is pretty much it. If you liked the write-up, share it with your network for more reach. You can read about me here.
Check out the Zero to Mastering Software Architecture learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.

I’ll see you in the next write-up. Until then. Cheers!


Follow Me On Social Media