
I wrote an article earlier on how YouTube stores petabyte-scale data every single day without running out of storage space. Do check it out.
In this one, I’ll discuss how the platform servers high-quality videos with such low latency. So, without further ado. Let’s jump right into it.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
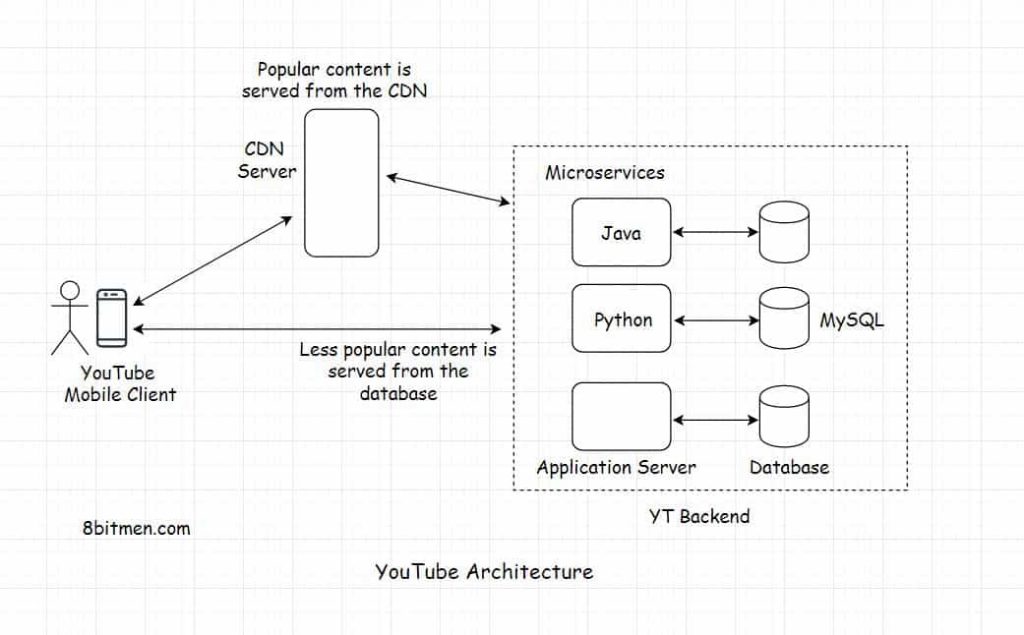
Here is the diagram for the high-level backend architecture of the video-sharing platform for reference. I’ve discussed the details in the YouTube data storage article I’ve linked above.
Let’s understand the key concepts in the video delivery flow.
Video Transcoding
A key element in the process of storage and delivery of high-quality videos on YouTube is video transcoding. When a video is uploaded on Youtube, it’s first transcoded from its original format to a temporary intermediate format to facilitate the conversion of the content in different resolutions and formats.
Video transcoding is a technique of converting a video into multiple different formats and resolutions to make it playable across different devices and bandwidths. The technique is also known as video encoding. This enables YouTube to stream videos in different resolutions such as 144p, 240p, 360p, 480p, 720p, 1080p & 4K.
Adaptive Streaming
The delivery of content based on the network bandwidth and the device type of the end user is known as adaptive streaming. Over the years YouTube has excelled at this. The goal is to reduce the buffering as much as possible.
Imagine streaming a 4K video at only its original resolution, with no lower resolutions. Without adaptive streaming, there is no way viewers with a low bandwidth network can watch that 4K stream. This is definitely not an end-user experience anyone would want on a platform.
You can read more on transcoding here & adaptive bitrate streaming here.
Codecs
Large video files are compressed into smaller sizes with the help of codecs. Codecs contain efficient algorithms that compress a video into smaller sizes. One of the most common widely used video codecs used today is H264. According to Wikipedia, this codec is the video compression standard and is used by over 91% of video industry developers.
Lossless & Lossy Transcoding
Video transcoding is possible in two ways lossless and lossy. You may have heard of these terms associated with data/image compression. Lossless means during transcoding from the original format to a new format, there is no loss of data. This means the new format video will also be mostly of the same size as the original video since there is no loss of data.
In the lossy approach, some data is dropped from the original video in order to reduce the size of the new format. Lost data cannot be regained. It’s gone forever. You might have experienced this when you upload a high-resolution DSLR camera image on a social network and after the upload, the image doesn’t look as good and detailed as the original image.
This is for one simple reason, the platform compressed the image shedding some data from it in order to reduce it in size so that your friends can easily view it without experiencing any sort of download latency. Videos are a series of still image frames. When you render an animation video the animation software generates the animation in frames and then we add all the frames together to create the final video. So, the same compression techniques apply to the videos as well.
Costs Associated with Video Transcoding
When a video is converted into multiple formats and resolutions, all the different versions need to be separately stored in the database. This has storage costs. Also, sophisticated codec algorithms that convert these videos into different resolutions have high computational costs. And then switching between different resolutions based on the client’s network bandwidth in real-time has network delivery costs. YouTube’s video encoding pipeline keeps a balance between the three factors. Additional efforts for further compressing the videos are made by the platform only for the highly popular videos.
Let’s move on to the video upload and rendering flow.
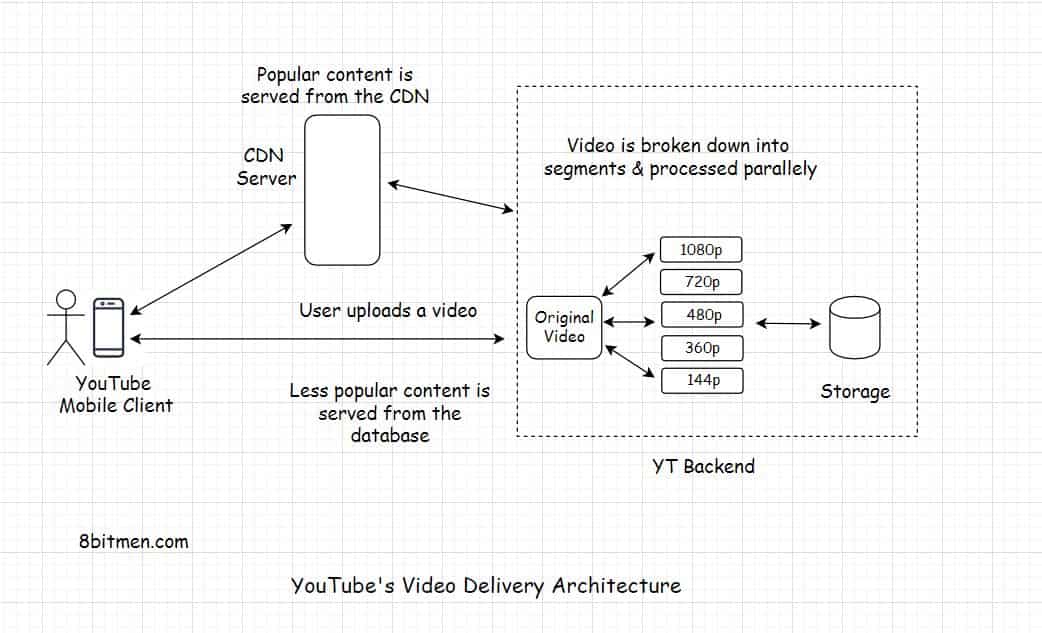
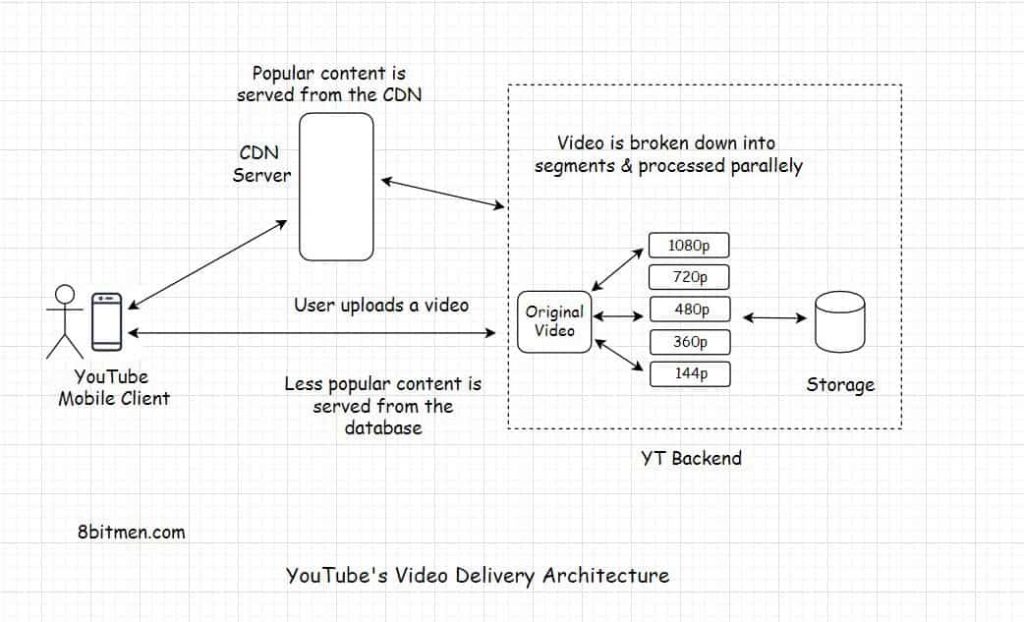
YouTube’s Video Delivery Architecture
All the videos that are uploaded to YouTube are first transcoded into multiple different formats and resolutions set by the platform. The video during the transcoding process is broken down into segments and converted into multiple different resolutions. The processing of multiple segments is spread across multiple machines to parallelize the process thus increasing the throughput. If a video goes viral, it is subject to another round of video compression. This second round of compression ensures the same visual quality of the video at a much smaller size.
When encoding videos YouTube chooses a bitrate within the limits that the codec allows. A video with a high bitrate has better quality but there is a sweet spot beyond which even on increasing the bitrate there is not a significant visual improvement in the video quality though the video size increases in the process.
YouTube also takes into account the playback statistics of the video player on the client’s device like how often the player switches to a lower resolution with respect to the steaming bandwidth available on the client, etc. It then predicts if better resolution content can be pushed to the user, being aware of their streaming bandwidth limit. This performance estimation enabled YouTube to cut down on bandwidth, subsequently increasing user engagement on the platform.
For encoding videos, YouTube uses VP9 – an open-source codec that compresses videos with HD & 4K quality at half the bandwidth used by other codes.
Once the videos are transcoded and stored in the database, they are spread across the cache network of the platform. When the user requests a video, the platform checks the viewer’s device type, screen size, processing capability, the network bandwidth and then delivers the fitting video version in real-time from the nearest edge location.
When the video is streamed LIVE, it’s not really LIVE. There is a slight processing delay required by the transcoding and other processes involved in the video delivery. Also, it’s tricky to cache LIVE videos across the network since it’s being streamed LIVE. I’ll discuss that in my next write-up in the architecture series.
Reference:
Datacenter as a computer – A whitepaper by Google research.
Check out the Zero to Mastering Software Architecture learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.

You can subscribe to my email newsletter to stay notified of the new content published on the blog.


Follow Me On Social Media