
YouTube database – How does it store so many videos without running out of storage space?
YouTube is one of the most popular websites on the planet. As of May 2019, more than 500 hours of video content is uploaded to the platform every single minute.
With over 2 billion users, the video-sharing platform is generating billions of views with over 1 billion hours of videos watched every single day. Boy! These are just incredible numbers.
This write-up is an insight into the databases used at YouTube and the backend data infrastructure that enables the video platform to store such an insane amount of data, as well as scale with billions of users.
So, here it goes.
Distributed Systems
For a complete list of similar articles on distributed systems and real-world architectures, here you go
1. Introduction
YouTube started its journey in 2005. As this venture capital-funded technology startup gained traction, it was acquired by Google in November 2006 for US$1.65 billion.
Before they were acquired by Google, the team comprised:
2 system admins
2 software architects that focused on the site’s scalability
2 feature developers
2 network engineers
1 DBA
2. Backend infrastructure
YouTube’s backend microservices are written using Python, C, C++, Java with Guice framework, and Go. JavaScript is used for the user interface.
MySQL is the primary database powered by Vitess, a database clustering system for horizontal scaling of MySQL. Memcache is used for caching and Zookeeper for node coordination.
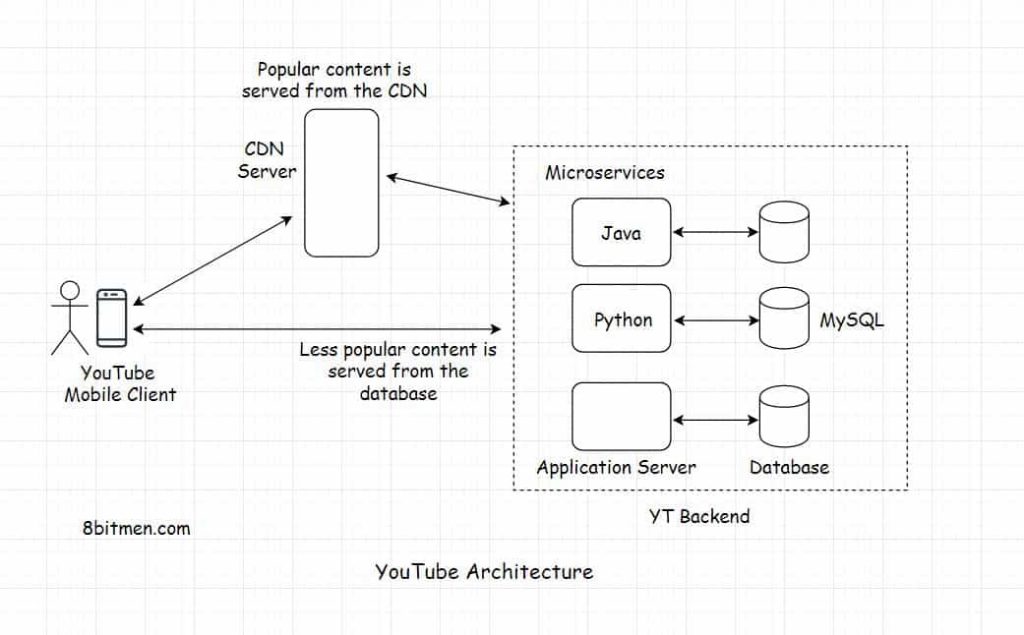
Popular videos are served from the CDN and moderately lesser-played videos are fetched from the database.
Every video, at the time of the upload, is given a unique identifier and is processed by a batch job that runs several automated processes such as generating thumbnails, metadata, video transcripts, encoding, setting the monetization status and so on.
VP9 & H.264/MPEG-4 AVC (Advanced Video Coding) codecs are used for video compression that encode videos with HD and 4K quality at half the bandwidth required by other codecs.
Dynamic Adaptive Streaming over HTTP protocol is used for the streaming of videos. It’s the adaptive bitrate streaming technique that enables high-quality streaming of videos over the web from conventional HTTP web servers. Via this technique, the content is made available to the viewer at different bit rates. YouTube client automatically adapts the video rendering as per the internet connection speed of the viewer thus cutting down the buffering as much as possible.
I’ve discussed the video transcoding process on YouTube in a separate article below.
How does YouTube serve high-quality videos with low latency? Check it out.
This was a quick insight into the backend tech of the platform. Now, let’s understand why did the engineering team at YouTube felt the need to write Vitess. What were the issues they faced with the original MySQL setup that made them implement an additional framework on top of it?
If you wish to take a deep dive into distributed databases covering topics like how databases manage significant growth, how they deal with concurrent traffic in the scale of millions, how distributed transactions work, how cross-shard transactions are designed, how relational databases are horizontally scaled and more, along with distributed system design, check out my distributed systems design course here.
This course is a part of the Zero to Mastering Software Architecture learning path that takes you from having no knowledge on the web architecture domain to being capable of designing large-scale distributed systems like a pro.
3. The need for Vitess
The website started with a single database instance. As it gained traction, to meet the increasing QPS (Queries Per Second) demand, the developers had to horizontally scale the relational database.
3.1 Master-Slave replica
Replicas were added to the master database instance. Read requests were routed to both the master and the replicas parallelly to cut down the load on the master. Adding replicas helped get rid of the bottleneck, increased read throughput and added durability to the system.
The master node handled the write traffic, whereas both the master and the replica nodes handled the read traffic.
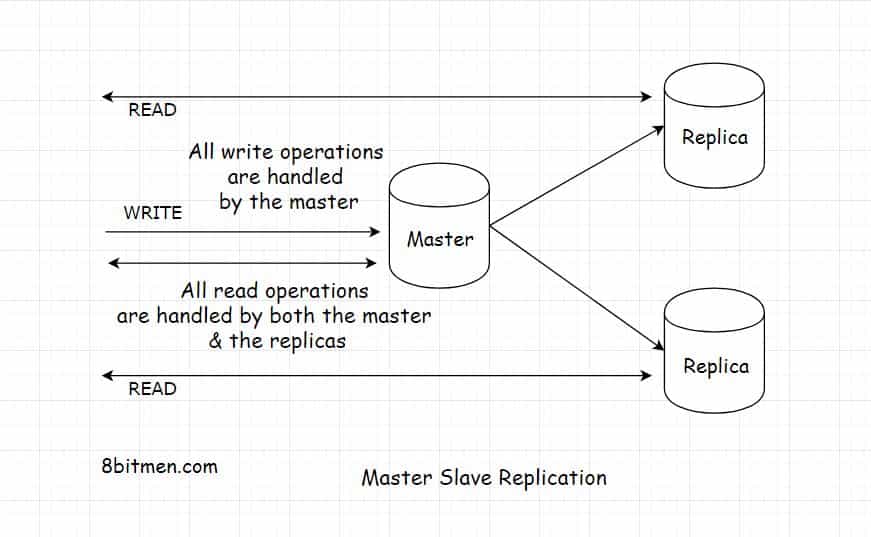
However, in this scenario, there was a possibility of getting stale data from the read replica. If a request fetched the data from it before it was updated by the master with the new information, it would return stale information to the viewer. At this point, the data between the master and the replica will be inconsistent. For instance, the inconsistency in this scenario can be the difference in view counts for a certain video between the master and the replica.
Well, this inconsistency is acceptable. The data between the master and the replicas would eventually become consistent. A viewer won’t mind if there is a slight inconsistency in the view count. It is more important that the video gets rendered in the viewer’s browser.
I’ve discussed this and related topics like eventual consistency, strong consistency, CAP Theorem, how data consistency works in a distributed environment, etc. in detail in my Zero to Mastering Software Architecture learning path. Check it out.
With the introduction of the replicas, the engineers and the viewers were happy. Things went smooth for a while. The site continued gaining popularity and the QPS continued to rise. The master-slave replication strategy now began struggling to keep up with the rise in the traffic on the website.
Now what?
3.2 Sharding
The next strategy was to shard the database. Sharding is one of the ways of scaling a relational database besides others such as master-slave replication, master-master replication, federation etc.
Sharding a database is something that is far from trivial. It increases the system complexity by a significant amount and makes management harder. Regardless, the database had to be sharded to meet the increase in QPS. After the developers sharded the database, the data got spread across multiple machines. This increased the write throughput of the system. Now instead of just the single master instance handling the writes, write operations could be done on multiple sharded machines.
Also, for every machine separate replicas were created for redundancy and throughput.
The platform continued to blow up in popularity and a large amount of data was continually added to the database by the content creators. To avoid data loss or the service being unavailable due to machine failures or any external unforeseen events, it was time to add the disaster management features into the system.
3.3 Disaster management
Disaster management means having contingencies in place to survive power outages, natural disasters like earthquakes, fires, etc. It entails having redundancies in place and the user data backed up in data centers located in different geographical zones across the world. Losing user data or the service being unavailable wasn’t an option.
Having several data centers across the world also helped YouTube reduce the latency of the system as user requests were routed to the nearest data center as opposed to being routed to the origin server located in a different continent. By now, you can imagine how complex the infrastructure had become.
Often unoptimized full table scan queries took down the entire database. The system had to be protected from bad queries. All the servers needed to be tracked to ensure an efficient service.
Developers needed a system in place that would abstract the complexities of the system, enable them to address the scalability challenges and manage the system with minimal effort. This led to the development of Vitess.
4. Vitess – A database clustering system for the horizontal scaling of MySQL
Vitess is a database clustering system that runs on top of MySQL and enables it to scale horizontally. It has built-in sharding features that enable developers to scale their database without adding any sharding logic to the application. Something along the lines of what a NoSQL database does.
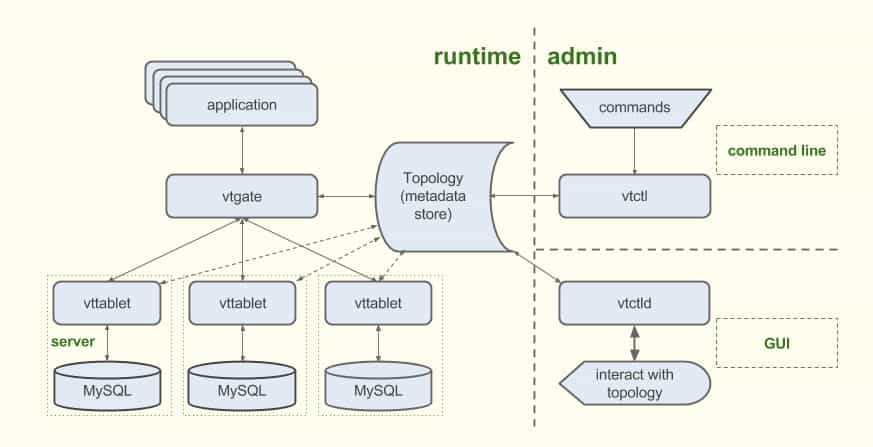
Vitess Architecture Image Source
Vitess also automatically handles failovers and backups, administers the servers and improves the database performance by intelligently rewriting resource-intensive queries and implementing caching. Besides YouTube, this technology is also used by other big guns in the industry such as GitHub, Slack, Square, New Relic, etc.
Vitess stands out when you cannot let go of your relational database because you need support for ACID transactions and strong consistency and at the same time you also want to scale your relational database on the fly like a NoSQL database.
At YouTube, every MySQL connection had an overhead of 2MB. There was a computational cost associated with every connection, also additional RAM had to be added as the number of connections increased.
Vitess helped them manage these connections at low resource costs via its connection pooling feature built on the Go programming language’s concurrency support. It uses Zookeeper to manage the cluster and keep things up to date.
YouTube’s backend #microservices are written using #Python, C, C++, #Java & Go. #MySQL is the primary #database powered by #Vitess for horizontal scaling of MySQL. #distributedsystems #softwarearchitecture
Click to tweet5. Deployment on the cloud
Vitess is cloud-native and suits well for cloud deployments as with it the database capacity can be incrementally augmented just like it happens in the cloud. It can run as a Kubernetes-aware cloud-native distributed database.
At YouTube, Vitess runs in a containerized environment with Kubernetes as the container orchestration tool. In today’s computing era, every large-scale service runs on the cloud in a distributed environment. Running a service on the cloud has numerous upsides.
Every large-scale online service has a polyglot persistence architecture as one data model be it a relational, document-oriented, key-value, wide-column or any other isn’t equipped to handle all the service use cases.
During my research for this article, I couldn’t find the list of specific Google Cloud databases that YouTube uses, but I am pretty sure it would be leveraging GCP’s unique offerings such as Google Cloud Spanner, Cloud SQL, Cloud Datastore, Memorystore and many more to run different features of the service.
Google Cloud Platform offers the same infrastructure that Google uses internally for its end-user products, such as Google Search and YouTube.
6. CDN
YouTube uses low-latency, low-cost content delivery using Google’s global network. It leverages the globally distributed Edge POPs (Points Of Presence) to enable its client to fetch data a lot quicker as opposed to fetching it from the origin server.
Upto this point I’ve discussed the database and backend tech used at YouTube. Time to talk about storage.
How does YouTube store such an insane amount of data (500 hours of video content uploaded every single minute)?
7. Data storage – How does YouTube stores such an insane amount of data?
The videos are stored in the hard drives in warehouse-scale Google data centers. The data is managed by the Google File System and BigTable.
GFS Google File System is a distributed file system developed by Google to manage large-scale data in a distributed environment.
BigTable is a low latency distributed data storage system built on Google File System to deal with petabyte-scale data spread over thousands of machines. It’s used by over 60 Google products.
If you wish to understand the underlying infrastructure on which our apps are deployed, how our distributed services are deployed across the globe in different cloud regions and availability zones and more, check out my platform-agnostic cloud computing fundamentals course.
So, the videos go into the hard drives. Relationships, metadata, user preferences, profile information, account settings, relevant data required to fetch the video from the storage, etc. go into MySQL.
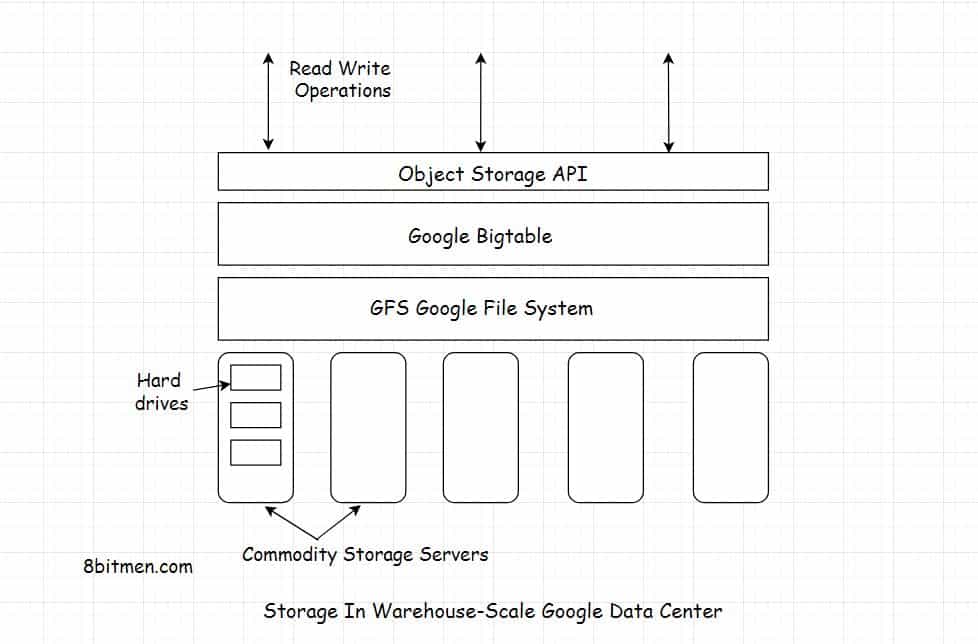
7.1 Plug and play commodity servers
Google data centers have homogeneous hardware and the software is built in-house to manage the clusters of thousands of individual servers.
The servers deployed that augment the storage capacity of the data center are commodity servers also known as commercial off-the-shelf servers. These are inexpensive, widely available servers that can be bought in large numbers and replaced or configured along with the same hardware in the data center with minimal cost and effort.
As the demand for additional storage rises, new commodity servers are plugged into the system.
Commodity servers are typically replaced as opposed to being repaired. Since they are not custom-built and can be manufactured in less time, they enable the business to cut down the infrastructure costs significantly in contrast to when using custom-built servers.
7.2 Storage disks designed for data centers
YouTube needs more than a petabyte of new storage every single day. Spinning hard disk drives are the primary storage medium due to their low costs and reliability.
SSD (Solid State Drives) are more performant than spinning disks as they are semi-conductor based but large-scale use of SSDs is not economical. They are pretty expensive and also tend to gradually lose data over time. That makes them not so suitable for archival data storage.
Besides, Google is working on a new line of disks that are designed for large-scale data centers.
There are five key metrics to judge the quality of hardware built for data storage:
- The hardware should have the ability to support a high rate of input-output operations per second.
- It should meet the security standards laid out by the organization.
- It should have a higher storage capacity as opposed to regular storage hardware.
- The hardware acquisition cost, power cost and maintenance overheads should be acceptable.
- The disks should be reliable and have consistent latency.
Recommended read: What does 100 million users on a Google service mean?
Check out the Zero to Mastering Software Architecture learning path, a series of three courses I have written intending to educate you, step by step, on the domain of software architecture and distributed system design. The learning path takes you right from having no knowledge in it to making you a pro in designing large-scale distributed systems like YouTube, Netflix, Hotstar, and more.

Folks, this is pretty much it. If you found the content helpful, consider sharing it with your network for more reach. I am Shivang. You can connect with me on X and LinkedIn. You can read about me here.
References
Scaling MySQL in the cloud with Vitess and Kubernetes
Scaling YouTube’s Backend: The Vitess Trade-offs – @Scale 2014 – Data
Seattle Conference on Scalability: YouTube Scalability
The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines


Follow Me On Social Media